

Brown University researchers have developed an artificial intelligence model that can generate movement in robots and animated figures in much the same way that AI models like ChatGPT generate text.
A document outlining this research is
published
on the
arXiv
preprint server.
The MotionGlot model allows users to easily input actions like “move forward a bit then turn right,” and the system will create precise depictions of these movements to control robots or digital avatars.
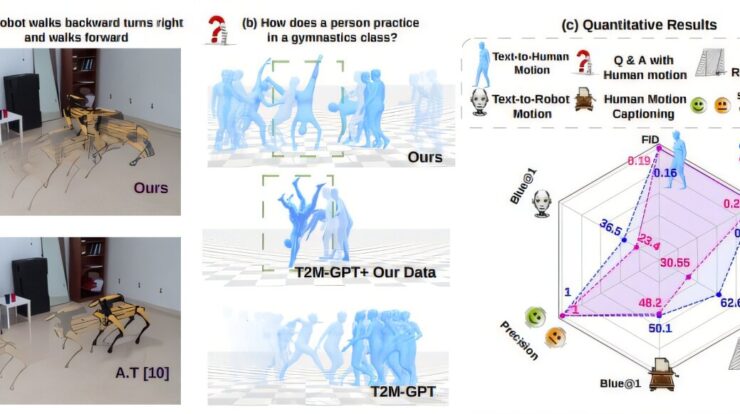
According to the researchers, the primary advancement of this model lies in its capacity to “convert” movement between different types of robots and figures, ranging from humanoid models to quadrupedal designs and more. This capability allows for the creation of movements suitable for various robotic forms and numerous spatial arrangements and scenarios.
Sudarshan Harithas, a Ph.D. student in computer science at Brown University, leading this research stated, ‘We’re viewing movement as an additional form of communication.’ He further explained, ‘Just like translating between different spoken languages—such as from English to Chinese—we can now convert command-oriented speech into equivalent movements applicable across various forms. This opens up numerous potential uses.’
The findings will be shared later this month at the
2025 Global Symposium on Robotics and Automation
in Atlanta. The work was co-authored by Harithas and his advisor, Srinath Sridhar, an assistant professor of computer science at Brown.
Large language models such as ChatGPT produce text via a mechanism known as “subsequent token forecasting.” This method involves dividing language into a sequence of tokens—these can be whole words or smaller segments like letters. When provided with one token or an array of them, the language model predicts what the following token could possibly be.
These models have proven highly effective in producing text, prompting researchers to adopt comparable strategies for motion generation. Essentially, they decompose elements of movement such as individual leg positions during walking into distinct units called tokens. After this segmentation, smooth motions can then be created via the process of predicting subsequent tokens.
A difficulty with this method lies in how actions performed by individuals of varying body types can appear quite distinct from each other. To illustrate, consider someone taking their canine companion for a stroll along the sidewalk: although they share the term “walking,” their movements vary significantly. The human remains erect using just two limbs, whereas the dog moves about on four paws.
As per Harithas, MotionGlot has the capability to convey the essence of walking across different forms. Hence, when a user instructs a character to “move ahead in a direct path,” the proper movement will result regardless of whether they are directing a human-like entity or a robotic canine.
To train their model, the researchers used two datasets, each containing hours of annotated motion data. QUAD-LOCO features dog-like quadruped robots performing a variety of actions along with rich text describing those movements. A similar dataset called QUES-CAP contains real human movement, along with detailed captions and annotations appropriate to each movement.
Using that training data, the model reliably generates appropriate actions from text prompts, even actions it has never specifically seen before. In testing, the model was able to recreate specific instructions, like “a robot walks backwards, turns left and walks forward,” as well as more abstract prompts like “a robot walks happily.”
It can utilize motion to respond to queries. Upon being asked, “Could you demonstrate movement in cardiovascular exercise?”, the model produces an animation of someone running.
They perform optimally when trained with extensive datasets,” Sridhar stated. “Should we manage to gather large-scale data, scaling up the model would be straightforward.
According to the researchers, the model’s present capabilities and flexibility across various forms hold potential for applications in human-robot interaction, gaming and virtual environments, as well as digital animation and video creation. They intend to release both the model and its source code openly, enabling other scientists to utilize and further develop this work.
More information:
Sudarshan Harithas et al., MotionGlot: A Multi-Embodied Motion Creation Model,
arXiv
(2024).
DOI: 10.48550/arxiv.2410.16623
Provided by Brown University
This tale was initially released on
Tech Xplore
. Subscribe to our
newsletter
For the most recent science and technology news updates.




